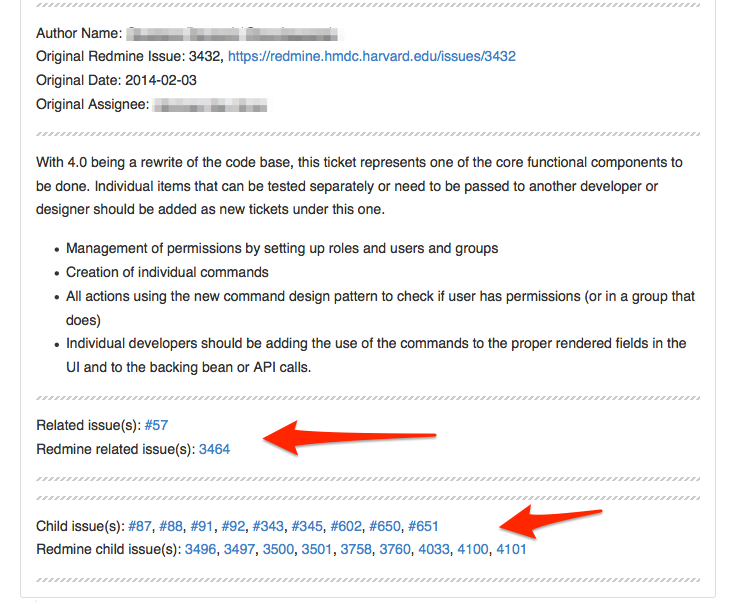
I just ran across this snippet from a hasty project last year. For a course database, an administrator needed an easy way to copy semester details via the admin.
Ideally, the user would:
(1) Check selected semester objects
(2) Choose “copy semester” from the dropdown menu at the top
These options are displayed in the image below.

The basics of admin actions are well described in the Django documentation.
For the screen shot above, here is the code used to copy the object, including ForeignKey and ManyToMany relationships. (Notes about the code follow.)
Location: admin.py
from django.contrib import admin
from course_tracker.course.models import SemesterDetails
import copy # (1) use python copy
def copy_semester(modeladmin, request, queryset):
# sd is an instance of SemesterDetails
for sd in queryset:
sd_copy = copy.copy(sd) # (2) django copy object
sd_copy.id = None # (3) set 'id' to None to create new object
sd_copy.save() # initial save
# (4) copy M2M relationship: instructors
for instructor in sd.instructors.all():
sd_copy.instructors.add(instructor)
# (5) copy M2M relationship: requirements_met
for req in sd.requirements_met.all():
sd_copy.requirements_met.add(req)
# zero out enrollment numbers.
# (6) Use __dict__ to access "regular" attributes (not FK or M2M)
for attr_name in ['enrollments_entered', 'undergrads_enrolled', 'grads_enrolled', 'employees_enrolled', 'cross_registered', 'withdrawals']:
sd_copy.__dict__.update({ attr_name : 0})
sd_copy.save() # (7) save the copy to the database for M2M relations
copy_semester.short_description = "Make a Copy of Semester Details"
Below are several notes regarding the code:
(1) Import python’s ‘copy’ to make a shallow copy of the object
(2) Make the copy. Note this will copy “regular” attributes: CharField, IntegerField, etc. In addition, it will copy ForeignKey attributes.
**(3) Set the object id to None. This is important. When the object is saved, a new row (or rows) will be added to the database.
(4), (5) For ManyToMany fields, the data must be added separately.
(6) For the new semester details object, the enrollment fields are set to zero.
To hook this up to the admin, it looks something like this:
Note “copy_semester” is added to the “actions” list.
class SemesterDetailsAdmin(admin.ModelAdmin):
actions = [copy_semester] # HERE IT IS!
save_on_top = True
inlines = (SemesterInstructorQScoreAdminInline, SemesterInstructorCreditAdminInline, CourseDevelopmentCreditAdminInline )
readonly_fields = ['course_link','instructors_list', 'course_title', 'instructor_history', 'budget_history', 'enrollment_history', 'q_score_history', 'created', 'last_update']
list_display = ( 'course', 'year', 'term','time_sort','instructors_list', 'last_update','meeting_date', 'meeting_time', 'room', 'number_of_sections', 'last_update')
list_filter = ( 'year', 'term', 'meeting_type', 'course__department__name', 'instructors' )
search_fields = ('course__title', 'course__course_id', 'instructors__last_name', 'instructors__first_name')
filter_horizontal = ('instructors', 'teaching_assistants', 'requirements_met', )
admin.site.register(SemesterDetails, SemesterDetailsAdmin)
And that’s it!