Can we trust anonymous Twitter users? Before writing this paper with my colleagues Eni Mustafaraj, Samantha Finn and Andrés Monroy-Hernández, I would think that it was not impossible. But this is the theme of the paper that Andrés is presenting this week at ICWSM 2012:
Hiding in Plain Sight: A Tale of Trust and Mistrust inside a Community of Citizen Reporters
Below is a brief description of our findings. (It may look a bit impersonal because it is extracted from the contents of a poster we created, but you will get the idea.)
The contributions of this paper can be described as follows:
- To the best of our knowledge, this paper presents the first analysis of the practices of a community of Twitter citizen reporters in a life-threatening environment over an extended period of time (10 months).
- We discover that in this community, anonymity and trustworthiness are coexisting. Because these citizens live in a city troubled by the narco-wars that have plagued Mexico since 2006, it is a great example of a community where anonymity of active participants is crucial, while lack of anonymity may be fatal.
- We describe a series of network and content based features that allow us to understand the nature of this community, as well as discover conflicts or changes in behavior.
INTRODUCTION
The large volume of user-generated content on the Social Web puts a high burden on the participants to evaluate the accuracy and quality of content.
We usually rely on known reputed news sources (NPR, NYT, BBC, Der Spiegel, etc.) to evaluate them. However, not every country has a free press or is willing or able to allow the international press to move freely. In some countries, like Mexico, journalists have been killed by organized crime or put under pressure by the authorities to stop reporting on certain events.
In the era of social Web, more citizens are reporting of newsworthy issues gaining reputation as citizens-reporters.
However, not everywhere in the world is there a right to and protection of free speech. In countries where the traditional media cannot report the truth, anonymity becomes a necessity for citizens who want to exercise their right of free-speech in the service of their community.
Is it possible for anonymous individuals to become influential and gain the trust of a community? Here, we discuss the case of a community of citizen reporters that use Twitter to communicate, located in a Mexican city plagued by the drug cartels fighting for control of territory.
Our analysis shows that the most influential individuals inside the community were anonymous accounts. Neither the Mexican authorities, nor the drug cartels were happy about the real-time citizen reporting of crime or anti-crime operations in an open social network such as Twitter, and we discovered external pressures to this community and its influential players to change their reporting behavior.
CREDIBILITY OF CITIZEN REPORTERS
When we read news, we usually choose our information sources based on the reputation of the media organization. We trust the news organizations, therefore, we expect that their reporting is credible, though in the past there have been breaches of such trust, and all media organizations have an embedded bias that affects what they choose to report.
Social media platforms specializing in organizing humanitarian response to disasters, such as Ushahidi, rely on people on the ground to report on situations that need immediate attention. Anyone can be a reporter.
However, this poses a new problem: how do we assess the credibility of citizen reporting?
Citizen reporting lacks the inherent structures that help us evaluate credibility as we do with traditional media reporting. But sometimes, citizen reporting might be the only source of information we might have.
How can we use technology to help us verify the credibility of such reports?
HASHTAG-DEFINED ONLINE COMMUNITY
To address this question we look at a particular community of citizen reporters gathered around Twitter accounts in a Mexican city plagued by drug-related violence.
Twitter has a unique feature that facilitates on-the-fly creation of communities: the hyperlinked hashtags. While previous research has shown that the majority of Twitter hashtags have a very short half-life span (Romero, Meeder, and Kleinberg 2011), in this paper we analyze the practices of a community of citizens that have been using the same hashtag since March 2010 to report events of danger happening in their city.
We refer to the community with the obfuscated hashtag #ABC_city, which is a substitute for the hashtag present in the tweets of our corpus. We will also substitute the exact text of important tweets with a translation from Spanish to English, so that searching online or with the Twitter API will not lead to unique results.
THE BIRTH OF A COMMUNITY: #ABC_city
Through research we discovered the birth of the community defined by the hashtag #ABC_city : The following tweet mentioning #ABC_city for the first time was the inaugural one, on March 19, 2010, by a not-particularly-active member:
#YXZ_city #ABC I propose #ABC_city to inform about news and important events in our city.
Then, this user reused the new hashtag many times in the following days together with #old_ABC hashtag and others, in order to spread its use:
@userA shootings are being reported in [address] (good source) #ABC #old_ABC #ABC_city #XYZ_city
In May 11, 2010, the same user who created the hashtag tweeted the following:
@Spammer101 Stop spamming #ABC_city. It’s only about important events that might affect our society.
Between May and November 2010 the usage of the hashtag is sparse, with the old hashtags being used more often. An increase in the adoption of #ABC_city starts on November 4th, only a week before the starting period of the #ABC_city dataset.
DATA COLLECTION
We used a basic dataset and a supplemental collection informed by our initial set of data.
The original dataset consists of 258,734 tweets written by 29,671 unique Twitter users, covering 286 days in the time interval November 2010 – August 2011.
On November 2010 we provided a set of keywords related to Mexico events to the archival service. The collection was later divided in separate datasets according to the presence of certain hashtags.
To supplement our limited original dataset, we performed a series of additional data collection in September, 2011. In particular, we collected all social relations for the users in the current dataset, as well as their account information.
We collected all tweets for accounts created since 2009 with less than 3200 tweets, in order to discover the history of the (anonymized) hashtag #ABC_city that defines the community we are studying.
We also made use of the dataset described in (O’Connor et al. 2010) to locate tweets archived in 2009.
THE NEED FOR DATA OBFUSCATION
While we would prefer to give further details on the collected data and use them freely in this paper, on ethical grounds, we will protect this community under anonymity, due to potential risk that our research can pose now or in the future. To exemplify the seriousness of the situation, we provide one example out of the many documented in the press of what the lack of anonymity can lead to.
On September 27, 2011, the Mexican authorities found the decapitated body of a woman in the town of Nuevo Laredo (near the Texas border) with a message apparently left by her executioners, which starts this way:

“OK, Nuevo Laredo en Vivo and social networking sites, I’m The Laredo Girl, and I’m here because of my reports, and yours, …”
Laredo Girl was the pseudonym used by the woman to participate in a local social network that enabled citizens to report criminal activities.
THE ACCOUNT @GodFather
Followee Relations Out of 29,671 unique users in the corpus, we were able to collect followee information for 24,973 accounts that were active and public in September 2011 (84% of all users in the corpus). There are more than 8,5 million followee links, with an average of 336 followees per user and a median of 162 followees. The total number of unique followees is almost 1,7 million.
Ranking the followees based on the number of relations inside this #ABC_city community serves as an indicator of the attention that this community as a whole pays to other Twitter users. We inspected the top 100 accounts to understand the nature of their popularity. The top account was Mexico’s president, Felipe Calderon, followed by the TV news program of the city, and an anonymous citizen reporter to whom we will refer as @GodFather. Four journalists, the city’s newspaper, a famous Mexican poet, and a comic’s character made up the rest of top ten. Almost half of the accounts in the top 100 are entertainers of Mexican fame, with only a few international superstars such as Shakira or Lady Gaga in the mix. This statistic confirms the widespread perception that a large part of the Twitter appeal derives from its use by celebrities, though it also indicates that each community is interested in its own celebrities. 25 of top 100 most followed accounts belong to local and national journalists and media organizations, compared to 10 for politicians at the state and federal level. In fact, the governor of the state in which ABC city is located (Mexico is a federation of 31 states) ranks at the 45th position in the followees list, one place behind the account of Barack Obama.
To understand the appeal to the community of the top 100 ranked accounts, we inspected their Twitter profiles. The top account, @GodFather, has 9,079 followers inside the community, or 36% of all active members. This amounts to 16% of all his audience, he has in total 57,127 followers. @GodFather is an anonymous citizen who has written the largest number of tweets in the corpus (6,675), which make up 25% of all his statuses (26,340).
FRIEND RELATIONS
A mutual-follow relation in Twitter (the friendship) is significant because it enables the involved accounts to send direct messages to one another. Direct messages offer some privacy to users, though if an account is hacked messages are compromised (unless a user has the habit of deleting them). Communication through direct messages is not visible to researchers or the public and cannot be quantified. However, it is possible to quantify the extent to which such strong ties exist inside the community by discovering mutual links in the sets of followers and followees. As shown below, on average, 40% of user relations are reciprocated.

The normal-like histogram of reciprocal link distribution of friendship relations (mutual links) in the network of the #ABC_city corpus.
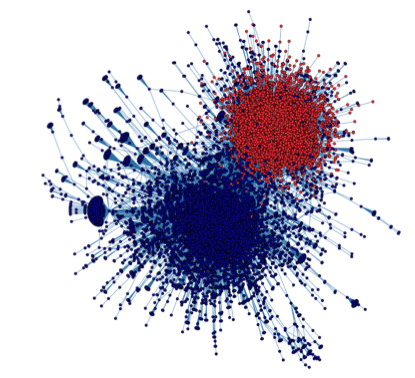
The next figure shows the graph of all members with more than 75 friendship links which only reinforces the conclusion that this is a tightly connected community of users. (We limited the number of nodes for computational reasons)

The graph of all members with more than 75 friendship links. Coloring is produced automatically by the Gephi modularity algorithm that finds communities in a network using the Louvain algorithm.
RETWEETING AS AN ACT OF CONVEYING TRUST
Past research has shown that retweeting is indicative of agreement between the original sender and the retweeter (e.g., (Metaxas and Mustafaraj 2010; Conover et al. 2011)). Over time, retweets are effectively providing information about a community of social media users that are in agreement on specific issues. Otherwise, the chance of a community member retweeting a message of an opposing political community is under 5%.
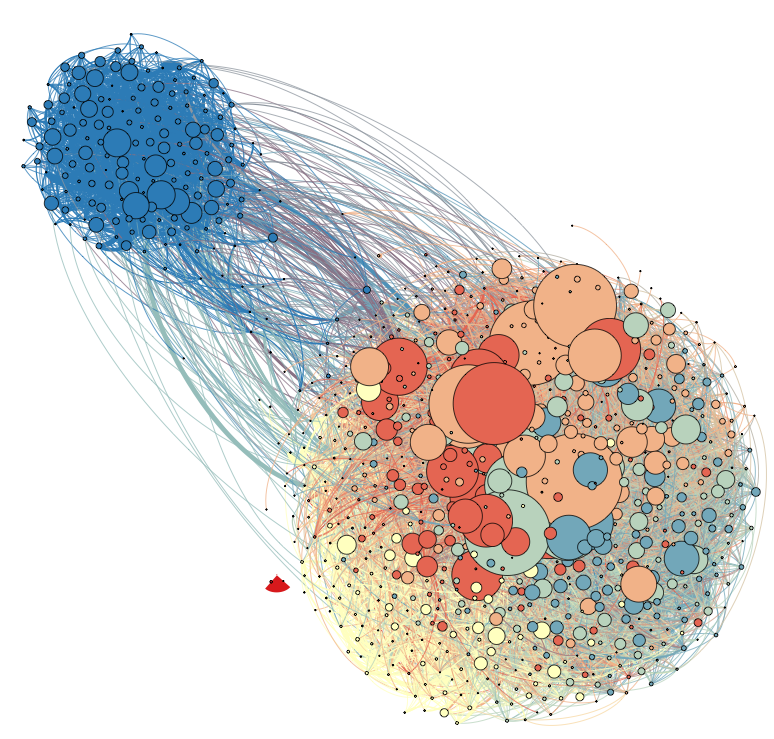
Since retweets involve a relation between two users, the original sender and the retweeting user, we can create a network of such relations for all retweets in the corpus. This retweet graph is shown below.
The retweet graph reveals a large component that is actively involved in retweeting, with smaller star-like components at the fringes. Closer examination reveals that the stars at the fringes were occasional retweeters of famous users (e.g., entertainers) and could easily be identified and excluded from our analysis. The nodes have been drawn in size relative to their in-degree, that is to the degree that their messages had been retweeted, revealing a small number of accounts that rose to prominence in the community.

Zooming in inside this graph reveals the most influential nodes in the community, which we identified as the anonymous citizen reporters. The biggest node belongs to @GodFather.

A closer look at the core of the community reveals 13 nodes that have a larger share of their messages retweeted. The spatial proximity of these nodes determined by a force-directed algorithm indicates that they were also retweeting each other (as opposed to the nodes in the periphery of the retweet graph). The biggest node belongs to @GodFather.
FREQUENCY OF COMMUNICATION

Tweeting activity of three groups of users with different tweeting patterns overlaid with the frequency of appearance for the word “balacera” (shooting). All three groups have an increase in activity, matching the ups of the balacera distribution. There is only one discrepancy, in April-May 2011, related to an event explained in the next section.
WHO DO YOU TRUST?

Daily distribution of tweets for the anonymous account @GodFather and its daily mentions in tweets by other members of the community. In April 2010, he was accused by newly created anonymous accounts of working for the criminal organization. After that event, he decreased his involvement in the community and at the end of July stopped tweeting altogether.
CONCLUSION OR
WHAT DOES IT MEAN TO BE ANONYMOUS IN A DANGEROUS ENVIRONMENT?
In a time when social networking platforms such as Facebook and Google+ are pushing to force users to assume their real-life identities in the Web, we think that it is important to provide examples of communities of citizens for which maintaining their anonymity inside such networks is essential. But being anonymous makes one more susceptible to denigration attacks from other anonymous accounts, leaving the other members of community in the dilemma of who to trust.
Inside a community, even anonymous individuals can establish recognizable identities that they can sustain over time. Such anonymous individuals can become trustworthy if their efforts to serve the interests of the community remain constant over time.

 It is not a 100% separation, but one can see that the false rumors (marked by red triangles) show low spread and high skepticism, while the true ones show high spread and low skepticism. The picture is of course muddled in the lower corner. A rumor that does not attract much attention did not have the opportunity to benefit from the “wisdom of the crowd” and thus cannot be determined by our system.
It is not a 100% separation, but one can see that the false rumors (marked by red triangles) show low spread and high skepticism, while the true ones show high spread and low skepticism. The picture is of course muddled in the lower corner. A rumor that does not attract much attention did not have the opportunity to benefit from the “wisdom of the crowd” and thus cannot be determined by our system.













 *
*