In the past few years, the emergence of “blockchain” and “cryptocurrencies” in popular media has skyrocketed. Blockchain is often heralded as a revolutionary technology that will change all aspects of life, from businesses to daily life. A quick google search of the term will prove fruitful, with millions of hits linking to newly authored books about the revolution, newly created businesses riding the frenzy, and new overnight millionaires who made their millions by trusting the system that is built on a lack of trust. But what is blockchain really? How does it work? And is this technology as revolutionary as people say it is? For the remainder of this post, I’ll focus on providing a high level overview of the first two questions and some thoughts about the role of blockchain technology going into the future.
First, what is blockchain?
Blockchain is the technology behind cryptocurrencies like bitcoin which is at its core a decentralized, growing list of immutable records that are linked using cryptography. That is, the blockchain, is literally just a chain (link) of blocks (think of an excel sheet or a list containing records) that aren’t stored in any single place (decentralized) and cannot be changed (immutable) and are expanded using common cryptographic methods. The fact that the list, which is commonly referred to as the ledger, is both decentralized and immutable are key to understanding the technology. The technology itself consists of three fundamental parts: (1) the ledger (the list of transactions), (2) A consensus algorithm (will expand on this shortly), and (3) the digital currency. Each of these pieces are essential to keep the blockchain active and growing.
First, the ledger. The ledger, as mentioned above, is simply a list. You can think of an excel spreadsheets with columns and rows in which a list is kept. So what is in the list? The list stores all previous transactions involving the cryptocurrencies, contracts, records, or other information. The ledger is equivalent to the blockchain itself. That is, the ledger is a chain of a bunch of blocks linked together, where blocks are defined as newly added transactions to the previous ledger, creating a new ledger with the new block chained at the end. And a cool aspect is that this list is decentralized, that is, the same list exists on multiple computers on a network of nodes. But, the list is also immutable, meaning that once a transaction is added to the list, it cannot be changed or removed. The two natural questions to ask at this point are: 1) how is it that the list is immutable? and 2) what happens if two lists have conflicting values (given that the lists are decentralized)? To explore the first question of immutability, I will describe at a high level of abstraction, where this immutability comes from (ultimately it relies on an inability to solve difficult mathematical problems quickly).
When new blocks are added to the existing ledger, they are added cryptographically (using a hash function). A hash function is simply a one-way function (easy to compute in one direction but not the other — usually based on mathematical problems like prime factorization which is a one way function because it is easy to multiply two large prime numbers together, but difficult to factor the product of two prime numbers) that takes in a large input (in this case, the previous ledger or blockchain combined with the new block) and outputs a condensed random string of characters called a hash. The previous ledger is represented simply by another previous hash from the ledger before that and the new block that was added, and so on and so forth, creating the chain. The immutability comes from the fact that if any part of the ledger is changed, then the hash will change completely. Anyone can check to make sure that the ledger matches the legitimate ledger by running the hash function over the ledger and making sure that the hash matches the one that is published, which is where the immutability comes from.
The second question about conflicting values leads us to the second core component of the blockchain technology, namely the consensus algorithm. The consensus algorithm simply takes different ledgers that may have gotten out of sync, and chooses the ledger that everyone will agree on based on which ledger most people have. This allows for the decentralization of the ledgers, so that not one authoritative body has a right to the ledger, but the ledgers still stay in sync and updated over time.
The final component of the blockchain is the digital currency, such as bitcoin. This aspect is incredibly important to the technology because this is where the incentive comes for people to buy into the system and continue to keep it going. There is no physical manifestation of this currency, but it is represented digitally and kept on the ledger. This leads us to the discussion of bitcoin “miners” a term that you may be familiar with. When a block is hashed along with the previous ledger, the hash function produces a hash of a list of random characters (base 16 including numbers and some chars). However, the creators of blockchain have decided that most hashes will not be accepted except for hashes that start with 6 leading 0’s. What this means is that a hash must randomly be generated that starts with 6 leading 0’s in order to be considered a valid hash. Because the hash function is random, there is about a 1 in 86million chance of generating a valid hash. When a person generates a valid hash and publishes it, they are rewarded with a fixed amount of bitcoin and the system continues on. Here is a helpful graphic from this website
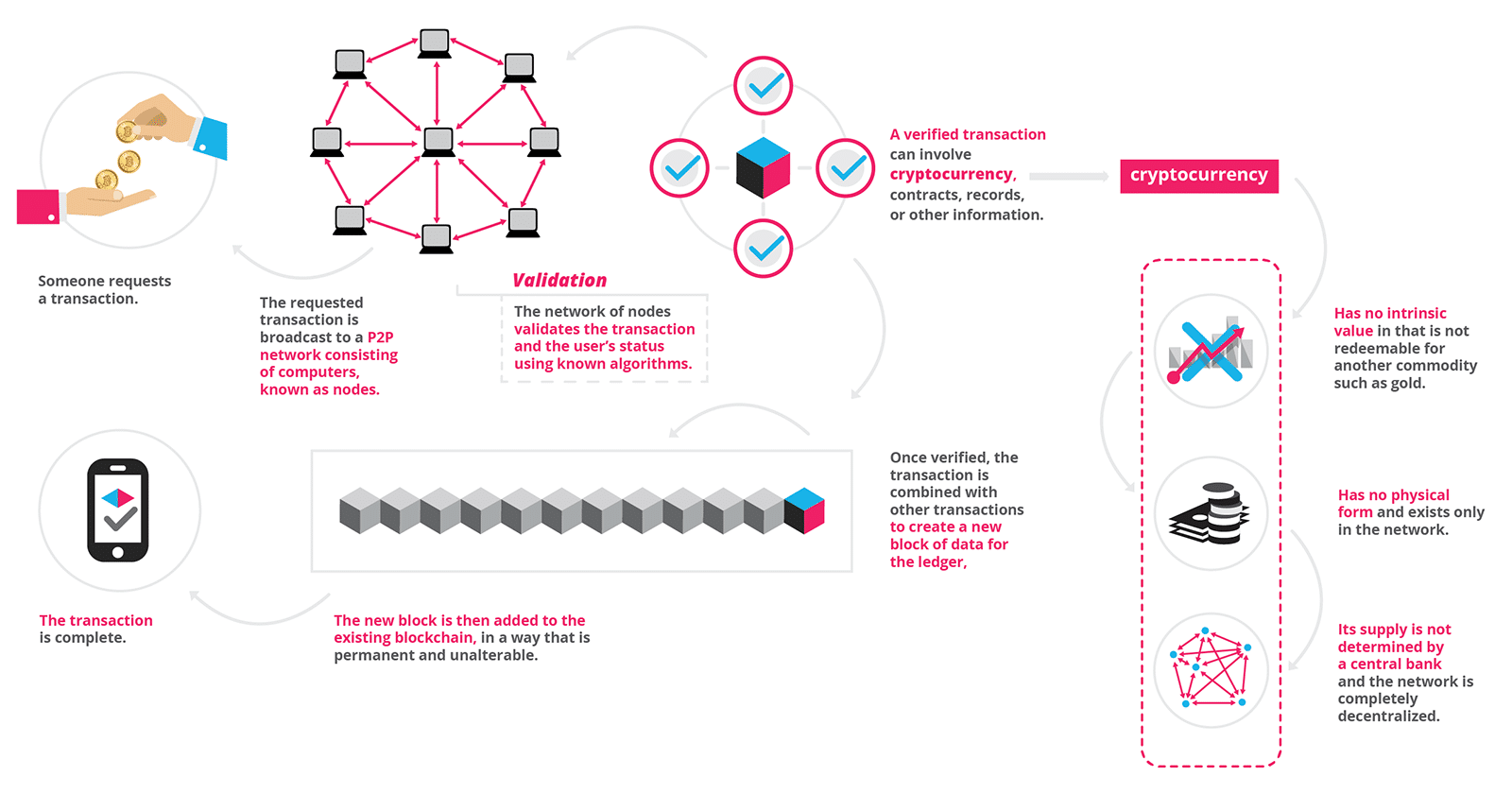
Given a quick, high level overview of the technology, it seems that the main draws of the technology are that it is a secure and decentralized manner to make transactions of just about anything. Given these benefits, it helps us to more clearly see the real benefits (and the lack thereof) of this technology in context. This technology is cool, but likely will not be a technology that revolutionizes all industries (as some hope). But, the technology does give us a secure outlet to make transactions in the future while keeping a list that we can trust will be safe from tampering in the future, which is helpful, but is a niche use-case that doesn’t extend as far as some of the hype entails. Rather than a solution to all problems, it seems that the blockchain is a potential solution to one problem, albeit a large one, the problem of making secure transactions.